Take turns sitting out a hand as the “fluffer.” The dealer deals two hands per player to the fluffer, and then the fluffer chooses half the hands to be used for the round. The intent is to force more excitement.
Tasting a Higher Proof
Fred Minnick just released his well-regarded ranking of the top 100 American whiskies for 2022. He started with 800 whiskies, and over several rounds, narrowed things down to his top 100. All else equal, I suspect that higher proof whiskies tend to do better in this ranking. Is this because undiluted, cask-strength whiskies are more complex in the nose, flavor, and finish? Or is the reasoning is circular — maybe the sort of whisky that does well undiluted is better. Maybe Fred just likes an efficient way to get buzzed?
To answer this question, I pulled Minnick’s top 100 picks into a spreadsheet and cleaned-up the data. Here is the distribution of the proof of the 100 whiskies:
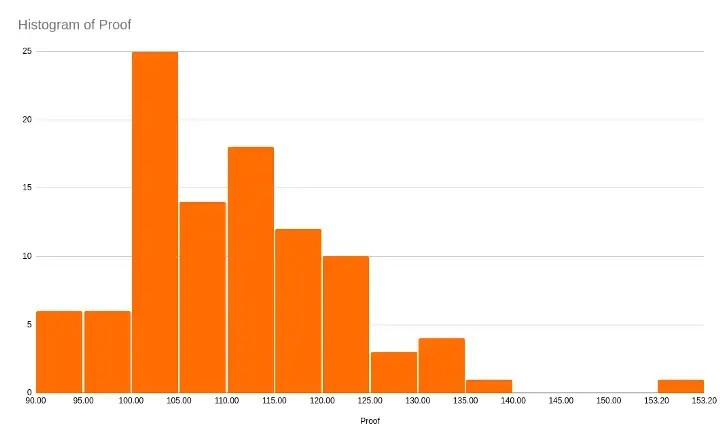
That outlier on the right is the infamous Jack Daniel’s Coy Hill.
Then I did a simple regression analysis. I use a whisky’s proof to predict its ranking. Since this is a very small dataset, I am doing traditional full-sample analysis, with no test set. It turns out, the proof (ha!) is there in the data: Minnick prefers higher proof whiskies. In fact, over 20% of the variation in his top 100 ranking can be explained by just the proof of the whisky! The relationship pops in a scatterplot:
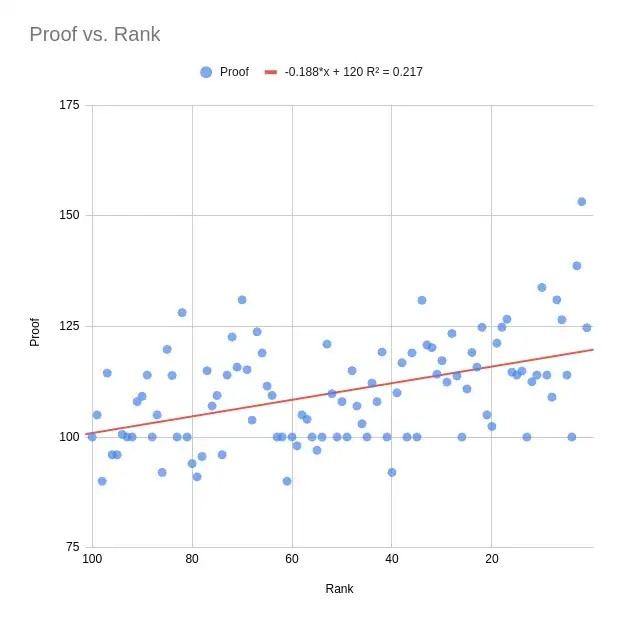
That coefficient of -0.188 on proof means that your whisky can improve its rank by 1 if you increase its proof by about 5. The relationship is weaker (14% explained) if you remove the top & bottom 5 proof whiskies as potential outliers.
Minnick does not seem to be biased by price. There is almost no relationship between a whisky’s price and its rank, especially when you throw out the pricey Michter’s 20 as an outlier.
If you combine both proof and price into a multivariate regression, you can explain a bit more of the variance in rank (about 25%). The data is here, if you want to experiment yourself.
Like the Electoral College but Worse
We should expect Trump to announce electoral victory on the night of November 3rd. Or earlier the next day. This will be due to some combination of stronger-than-expected in-person voting results and discrediting mail-in votes due to supposed fraud. By this point, ACB will be seated on the Supreme Court. With Florida in 2000 as precedent, the Democratic leadership would do everything possible to avoid a Supreme Court decision.
Trump may be ahead in some states’ early & in-person vote counts, but with small enough margins that the expected “blue shift” in mail-in votes would swing to Biden. These are your classic swing states. Importantly, some of these states have divided government, with Democratic governors and Republican control of the state legislatures. The 4 divided swing states are Michigan, North Carolina, Pennsylvania, and Wisconsin.
MI’s lower house is at stake in November, and will probably stay Republican. Both of the houses in NC & PA & WI are at stake, and all 6 will probably stay Republican. NC’s Democratic governor Roy Cooper is running for reelection, but seems safe. So we can expect the 4 divided swing states to still be divided before and after the election.
The 4 divided swing states may each submit two conflicting slates of electors, like several states did in 1876 and Hawaii in 1960. At the time, voter fraud and disenfranchisement were again the center of controversy.
There is enough ambiguity & confusion around the Electoral Count Act of 1887 passed after the 1876 drama for the elector slate of the state governor or the slate of the legislature to carry — and also around which federal house accepts the counts. There is an interpretation that would completely exclude conflicting electoral slates. Given that the 4 divided swing states have a total of 61 electors, this could mean both Trump and Biden fail to achieve the electoral majority. In this scenario of no electoral majority, the state delegations in the federal House of Representatives vote for the president. Given the very real pandemic and very fake mail-in vote fraud, maybe a state is confused about its own voting. So, “just” let its representatives vote instead…
The state delegation vote is an extremely undemocratic version of the already-undemocratic electoral college: Each state gets a single vote. Here the state of Delaware is literally as important as California!
State delegations would vote by simple majority of representatives in the House of Representatives. (Not the Senate.) The Democratic party has 22 state delegations, while the Republicans have 26, and 2 delegations are tied. Of the tossup House of Representatives elections, 7 representatives could swing their state’s delegation majority from Republican to Democratic. The Democrats would need a net gain of 4 state delegation majorities to get the majority of 26 of 50 state delegation votes.
In order of increasing margin-of-victory for Trump in 2016, the 7 tossup House seats that would swing a state delegation majority are currently held by Brian Fitzpatrick (PA-01), Fred Upton (MI-06), Scott Perry (PA-10), Justin Amash (MI-03), Ross Spano (FL-15), Don Young (AK-AL), and Greg Gianforte (MT-AL). Here PA and MI are somewhat double-counted, since all else equal, only one of the seats held by Fitzpatrick & Perry would need to flip to flip the state delegation. The same for Upton & Amash in MI.
Justin Amash (MI-03) is retiring, Ross Spano (FL-15) was not re-nominated, and Greg Gianforte (MT-AL) is retiring to run for governor. The other 4 are running again in their districts as incumbents.
In this not-entirely implausible scenario, each of these 7 representatives faces three potential outcomes: a) Their district stays Republican, and they vote for Trump in the state delegation; b) The tossup district flips to a Democratic representative, but the incumbent Republican “goes faithless” and votes for Trump in the delegation anyway; or c) The district flips Democratic, and the representative votes for Biden. Also keep in mind that Justin Amash (MI-03) is a Libertarian Trump critic who left the Republican party.
Pelosi and the Democratic leadership should be focused on these 7 house races, as well as fervently horse-trading to encourage the Democratic flip scenario. Get those seven to commit to following the wishes of their constituency, any mandate from two years ago be damned!
Bro. Do you even bake?
The recipe for the famous Tartine country loaf is less helpful than advertising for the bakery and new age woo woo. Pretentious garbage, really. Here is my consolidating upon a practical, clear recipe for sourdough bread. The only ingredients should be flour, water, and salt. The bread should be a crusty, rustic, (mostly) whole grain.
Grow a Starter
In the morning, add 100g of unsifted, all-purpose (AP) flour and 100g of water to a tall, lidded, glass jar. Stir with a spatula, and leave it sit, covered in a warm place all day. The environment should be distinctly warm, and so this often means turning on the oven at its lowest setting for a few hours (e.g. bake at 170°F).
Every morning, pour off all but about 125g of the starter. Use this poured-off batter to make a fry bread with sesame oil & scallions & five spice, or do something fancier. Add 50g of unsifted AP flour & 50g of water to the starter, stir with a spatula, and scrape down the insides of the jar. As usual, the environment should be warm.
Your starter is ready for bread when it is frothy & bubbly, and doubles in size by the afternoon. This will probably take a week-or-so of daily feedings.
Make a Leaven
The night before you want to bake bread, spoon a heaping tablespoon of starter into a large glass bowl. Add 75g of warm (80°F) water, and 75g of unsifted AP flour, and stir with a spatula. Cover the bowl with plastic wrap, poke a few holes, and leave it to sit overnight at room temperature.
After making the leaven, tuck your starter into the refrigerator and stop feeding. When you want to bake bread again, remove the starter from the refrigerator in the evening, and feed it in the morning as usual for a few days.
The next morning, confirm that a teaspoon of your leaven spooned off the top can float in a bowl of water. Your leaven may need more time or warmth. If so try again at lunchtime.
Mixing
Add 650g of warm (80°F) water to your leaven, and stir it until only a few clumps remain. Add 325g of unsifted AP flour and 700g of unsifted whole wheat flour to the bowl. Work the dough until all the flour is just wet. Let this rest covered for 45 minutes, for the autolyse.
Dissolve 20g of salt in 50g of water. Use a salt with lots of minerals, like sea salt or even plain ‘ole iodized. Pour the salt water over the dough, and repeatedly pinch to incorporate.
This dough is about 71% hydrated, ignoring that first tablespoon of starter. This dough is relatively stiff, especially compared with the trendy overly-hydrated recipes.
Fermentation
Leave the dough covered at room temperature. Every 30 minutes, with your hands wet from washing, pull up & fold the dough from the side of the bowl. Do this 4 times with a quarter turn of the bowl between each folding. So that’s 4 folds every 30 minutes for 3 hours. Put 6 counters next to the bowl as a physical mnemonic, removing one each folding.
Shaping
Cut the dough in half with a metal dough scraper. Half of the dough will be about 955 grams. Punch and fold out internal air pockets, and then scoop the two boules into rough spheres. Cover the boules with bowls, and let them bench rest for 30 minutes.
Using a metal dough scraper, pull the boule of dough along the sticky countertop, to develop surface tension. Turn the football shape and pull again. Do this just until a bit of tearing occurs on the surface.
Generously flour a clean towel with rice flour, firmly pressing the rice flour into the towel. Flip a boule onto the center of the floured towel, leaving the seamed side facing upward. Lift the boule and its towel like a hammock, and drop it into a large bowl or bread basket. Cover, and repeat with the other boule.
Proofing
Leave the bowls in the refrigerator overnight, to proof.
Baking
Preheat the oven to 500°F. Place a sheet of parchment on top of an oven-proof plate, and turn the parchment & plate upside-down onto one of the proofing bowls. Flip the whole bundle upside down, to drop the boule onto the parchment. Set aside the towel and proofing bowl. Brush off the rice flour.
Score the top of the boule deeply with a wet knife.
Cover the plate, parchment, and boule with the base of a dutch oven. (Do not use the lid.) Bake for 20 minutes. Reduce the temperature to 450°F, open the oven door briefly to cool the oven, and bake covered for another 10 minutes. Remove the dutch oven from the plate & parchment, and continue to bake uncovered for 25 minutes. Cool the boule.
Going Out While Social Distancing
Wanna go to that kaiseki in The Mission? They have a 7 address, so our whole crew will be there.
My ‘rents just moved into the 123 High Street building. Now we can meet at the pub on the corner.
He does not stand a chance of a getting a star in Fam Three. The empty storefront next door is in Fam Five, though.
I expect us to be playing whack-a-mole with this pandemic for a few years, and am worried some indulgences of modern life will never come back. For example, fine dining is damn-near-impossible to do virtually. I have a background in the hospitality industry, and have had the privilege to eat some amazing meals in my life. So this is personal.
Now by fine dining, I mean the by-definition pretentious, wasteful, and amazing conversation between diner and chef via the medium of tiny bites on giant white plates. A prix fixe or à la carte menu enjoyed with wine & company over a few luxurious hours. Including the dreaded communal table thing too, I guess. But how are we going to eat at fancy restaurants while we continue to socially distance? And how are restaurant employees going to get back to making a (modest) living? Take-out fried chicken & cocktails from a Michelin star place desperate for cash flow just ain’t financially sustainable. Crenn is doing fancy comfort food like it’s October of 2001, but how is she going to pay rent in Russian Hill on $55 per head?
Lately a lot of my research is connecting a company’s stock price with the digital exhaust left when we interact with the world. A challenging part of the job is controlling for the bias in a cohort of people. When is a group actually representative of a population, or actually random? So while I am nothing close to a computational epidemiologist, and while every machine learning & data scientist is pretending to be a virus expert this week, I have one idea that might help with fine dining while we are in social isolation.
Take a Number for Going Out
 Imagine getting your driver’s license or passport checked at the entrance of a restaurant, where they confirm one simple fact: What is the last, right-most, least-significant digit of your mailing address? (Ignore fractions.) This digit is your membership in an slightly-different, in-real-life family — in which of ten virtual neighborhoods do you arbitrarily belong? And importantly, does your number match the last digit of the restaurant’s address? If the two IRL Fam numbers do not match, the restaurant would be mandated to refuse service. That’s it. Think through some implications of this simple restriction:
Imagine getting your driver’s license or passport checked at the entrance of a restaurant, where they confirm one simple fact: What is the last, right-most, least-significant digit of your mailing address? (Ignore fractions.) This digit is your membership in an slightly-different, in-real-life family — in which of ten virtual neighborhoods do you arbitrarily belong? And importantly, does your number match the last digit of the restaurant’s address? If the two IRL Fam numbers do not match, the restaurant would be mandated to refuse service. That’s it. Think through some implications of this simple restriction:
Maintains Social Isolation
When you go out to eat according to IRL Fam number, you are only ever physically near a fraction of the people in the world. And importantly, these people are always a semi-random subset of the same fraction of the population. The only people who are eating at the restaurant tonight are those who have the same number, those who are in the same IRL Fam. You might even get to know each other.
This is different from just going to local restaurants in the your zipcode, where a rando might jump a cab from across town for the restaurant’s particular charm. (This is especially relevant for experimental or avant garde places that have never relied on walk-ins.) The IRL Fam system is also fundamentally different from going to a different, random restaurant every weekend, because in this case you would still be exposed to a random set of people. And this is very different from restricting the number of people in a particular restaurant, simultaneously. A recent study from Cornell showed how even very small classes still would leave the student community highly connected. This would also thrash most restaurant’s finances.
What’s an address in 2020?
We could theoretically assign a random number, or use your mobile phone number, or even (shudder) use a Social Security number. However, there are additional benefits to using a physical, mailing address for layering our virtual spatial separation atop the existing physical world. Using your mailing address defaults a specific set of people into breaking your social distancing rules: Your roommates, family members, and those in your apartment building. Assuming you still like your kids & spouses after shelter-in-place eases, these are exactly the people you usually want to go out with. And these are the people from whom you are de facto not social distancing from, anyway! You share the same space, breath the same air, push the same elevators buttons, and so on.
What about the service?
This might require that restaurant employees only work full-time, and only at a single establishment. Would employees also need to have a matching IRL Fam? I think that would be too extreme, but goes in the right direction. Maybe we finally abandon the bullshit labor arbitrage of the gig economy, and pass a law establishing full-time de facto employment (i.e. benefits) for anyone who is works 40 hours a week for the same legal entity. San Francisco is already doing this with Uber drivers.
When’s your birthday?
This is no more a violation of privacy than when nightclub security checks the ID of your date who is looking particularly baby-faced tonight… Let’s mandate zero record-keeping or data retention on the IDs themselves, once the IRL Fam number is confirmed. I suppose patrons would need to have an ID with a mailing address on hand, which is a admittedly a bit classist.
Do they have valet parking?
Here is a significant downside. If you are not allowed in 90% of the restaurants in town, you are more likely to drive further to find an interesting one in your IRL Fam.
Is this all a game?
Given the prevalence of mostly-empty nightclubs with long lines, there is a chance the artificial exclusivity of the IRL Fam system would be fun and dramatic. An apartment with an address matching The New Hotness restaurant would be more desirable. And ironically, this exclusivity would be arbitrary and therefore, relatively fair!
Scaling & the Resurgence
This system could start in a traditionally-quirky place like San Francisco, and expand to restaurants & clubs & bars in other cities. And when the next pandemic (resurgence?) inevitably pops up, when the next shelter-in-place mandate occurs, contact tracing via IRL Fam number would be easier.
Saison
Dinner at Saison was really solid. Spectacular service with attention to detail, an open kitchen with almost-haphazard arrangements of tables around the high-ceilinged, taxidermied space. The smell of the wood-fired stove filled the room. Our winter menu was from late December, 2019. My favorite beverage was a sake, Shirataki’s Jozen Mizunogotoshi (junmai ginjo).
- We started with champagne and tea made from a bundle of herbs in water. This reminded me of putting a sachet of herbs de Provence in a broth.
- Then tiny cuts of sea bream sashimi seared on charcoal, served with sea lettuces, orange yuzu, sesame seeds in an oil, and sriracha chili water.
- Lovely “nose to tail” dish of dungeness crab, featuring every part of the animal including the tomalley. Served with a thick almond milk sauce, and grapefruit.
- Seared scallop in an oily berbere-like sauce. My wife had a tofu dish with carrots & kimchi.
- Then we had trout with its roe alongside fartichokes, higher quality than the aquacultured McFarland Springs trout that’s everywhere else now-a-days.
- Tiny white bread poppy seed rolls, served warm in a little basket on the table.
- Black cod served with a chestnut puree, and a punchy (miso?) broth.
- One of our favorite items was uni served over a piece of grilled sourdough, looking a bit like nigiri. The texture was wet from a bread sauce being spooned over, presumably made from their house-fermented bread hanging above the kitchen.
- Spectacularly-beautiful radish dish, with a variety of colorful radishes & radish greens & flowers presented on a high, white plate.
- Venison loin sous vide with raw garlic inside, in a demi sauce with ribbons of pickled kohlrabi & grated horseradish, and chanterelles.
- The standout of the meal was the roasted honey nut squash mashed with a crunchy breadcrumb & herb mixture that tasted like Israeli salad.
- Weak cheese course that was a bland, soft buffalo cheese wrapped in banana leaves and served with a nice flatbread cracker. Given the high bar of Saison’s ingredients, I would have preferred an actual, editorial cheese course.
- Then a persimmon and creme fraiche dish, less savory.
- The first dessert was a disappointment. Something with candy cap mushrooms & chocolate & tea, but the mushroom just ate gimmicky. I would preferred something baked cake-y or tart-y with more crunch, acid, and texture.
- The second dessert with huckleberry & yuzu was for my birthday, and was very nice.
Philanthropy Picks (2019)
Here is a list of the philanthropies and charities where we donated this Giving Tuesday, after another messy year of the Dumpster administration:
- American Civil Liberties Union (ACLU, about 14%)
- Doctors Without Borders (14%)
- Earthjustice (14%)
- Electronic Frontier Foundation (EFF, 14%)
- ProPublica (14%)
- Refugee and Immigrant Center for Education and Legal Services (RAICES, 14%)
- Southern Poverty Law Center (14%)
Texas Hold ‘Em Variant: Buying the River
Texas Hold ‘Em is usually what people mean when they think of poker now-a-days. After the last poker night I attended, I thought of a variant of Texas Hold ‘Em inspired by the card shopping in Dominion that adds more reveals of partial information to the game, while keeping things essentially Texas Hold ‘Em -like.
- Give each player at the table three pips or markers unique to the player. Each player could have three pawns of the same but unique color, or three glass stones, or coins, or whatever. One of the three pips should sit in front of the player’s seat for the entire game, so it is easy to identify which player is which color (e.g. “Ben is the green pips”).
- Play your hand of Texas Hold ‘Em as usual, until after the betting round following the flop. At this point, each player can make a five card hand with their pocket cards and the flop.
- Flip up the turn (fourth) card. At this point players conduct a betting round for the “purchase” of the card. Importantly, folding in the turn card’s betting round does not knock the player out of the hand. Folding just means the player is not allowed to use the turn in their final hand. Sticking around until the pseudo-showdown of this betting round means the player is allowed to use the turn card in their final hand. A player indicates that they have made it to the turn card’s showdown, and therefore may use the turn card in their final hand, by placing one of their three pips on the card. All money bet in the turn card’s betting round is placed in the communal pot, as usual. To keep things simple, players should probably not be allowed to go “all in” on the turn card’s betting round.
- Flip up the river (fifth) card, and do a second purchase betting round just like the round done for the turn card. Again only players who make it to the river card’s showdown may use the river in their final hands.
- When all players have access to five to seven cards to make their final hands, do one final betting round. This final betting round reverts to the usual rules, where folding means dropping out of the hand.
Notes on The Man Who Solved The Market (Jim Simons)
Like seemingly everyone who works on the buy side, I have been reading the Zuckerman book about Jim Simons of Renaissance. The book spends a lot of time with the big personalities who have worked at Renaissance over the years. However there are some mathematical and technology hints:
Jim Simons’s academic field is geometric invariants in algebraic geometry.
Renaissance Technology worked with hidden Markov models, fit using the Baum-Welch algorithm. This algorithm has a Bayes update step, and a backward & forward process that feels like backprop. They also used high-dimensional kernel regression.
Henry Laufer worked with (vector) embeddings, very early. He also pushed for a single cross-asset and cross-asset-class model, so they could use all the cleaned “pricing” (market) data. They included assets with known bad data, but assets that nonetheless looked like existing assets in the model. This is maybe what we would call clustering, now-a-days. Everyone had access to the source code, even the administrative staff at first.
They tempted academics by working just one day per week, to see if they found trading interesting. They explicitly avoided trying to find economic sensibility for their strategies, but still followed a “scientific” method.
René Carmona imputed market data, which seems controversial.
Jim Simons invested in private companies alongside the systematic trading, especially in technology companies. This is probably because of the Nasdaq bubble.
They used a simple day-of-week seasonality model, at least for their futures trading.
They provided liquidity when “locals” de-risk, being in the “insurance business”.
They had a betting algorithm around the probability of moves in futures, not used for stocks at first. This was presented as opposed to statistical arbitrage with a factor model.
Their stock transaction cost model was the “secret weapon”. It was self-correcting, by “searching for buy-or-sell orders to nudge the portfolio back”. This increased their holding period to two days, on average. The strategy had very low capacity at first, however. In general they were not the best at trading, but at “estimating the cost of a trade”.
Around the time of the Nasdaq bubble bursting, they were trading 8,000 stocks. However this strategy was only 10% of the business. The futures strategy was still the mainstay, which was probably their chartist model.
Their use of basket options were 1) a tax optimization, but also 2) a way to cap downside, 3) isolate risk, and 4) increase leverage.
The internal Medallion fund is short-term, capped at $5b capital with all external clients eventually bought-out. The maximum capital is difficult to reconcile with Jim Simons’s compensation motivation, so it probably reflects limited capacity of the strategy, which means it trades in less liquid, smaller stocks and futures. In 2002 they were running 12x leverage in Medallion ($5b capital, $60b exposure given options).
They sought out astronomers because of their understanding of low signal-to-noise problems. Their named “Déjà Vu” strategy seems like a pairs or cointegration strategy.
Their strategy gets a 50.75% hit rate.
Why write this book now? Jim Simons is nearing the end of his career. Could also be transparency after the Mercers helped get Trump elected.
They at least use the terminology of risk factors and baskets: “RenTec decrypts them [inefficiencies]. We find them across time, across risk factors, across sectors and industries.”
The author uses strange terminology, suggesting that Zuckerman has actually not talked with many quants. For example, “trenders” for momentum style traders, and “data hunters” instead of “data scientists”.
Also the anecdote about Magerman unleashing “a computer virus that was infecting Renaissance’s computers” is clearly bullshit, and in a way that makes me doubt the author’s understanding of technology in general.
Review: Al’s Place
(1 out of 5 stars)
If you were to draw-up a list of the saddest fashions, affectations, ill-placed culinary passions, and grande cooking mistakes of the last few years, I think Al’s Place would solidly tick Every. Single. Box. This place is a living, breathing, performative satire of what fine dining should be.
First the place has no air conditioning and a single, beleaguered bathroom. I stood in line waiting to wash my hands, sweating from the warm San Francisco evening, and swapped places with a pregnant woman behind me who was certainly in more dire straits.
Clearly someone has pretenses of being a DJ, since they blare music so loudly that I could not hear anyone at my table a couple feet away. This was the recurring leitmotif of our dinner, and the main reason every one of us was hurrying through our mains and skipping dessert to just get out. Our first server was replaced by someone manager-ish, but they nonetheless misheard part of our order and just straight-up missed one of our wine requests. Each time we caught the attention of a new server, food runner, or host, we adulted and asked that the music be turned down. Call me crazy, but sometimes I go to a restaurant to get to know my companions better, as well as eat some neckbeard / topknot’s confusion cuisine. One of the servers eventually said the loud music was just the “vibe” of the restaurant, and we literally laughed out loud. At one point the woman at the table next to me leaned over, closely, to commiserate about the music. Most of the people in my row of table seats were physically leaning forward to yell. The place was so loud that when we asked for bowls for our shared soup, we were told they had heard us say we did not want them. And so on. The music itself? The usual quirky and dated garbage from the 90s, with a whiff of the post-ironic.
Their menu is a complete mess. First of all, they are too lazy to time the meal correctly and plate their dishes. Al’s Place calls this “family-style” or something, but its just cynical. Compounding this, neither of our two servers could actually tell us how much food to order for our party size, because there was no relationship between the section of the menu and the amount of food that ends up in front of you. There was some myth-making about “chef” wanting to treat proteins as a side, because they think this a comment on steak houses. But note that a real steak house can serve a plate of hot food umm, hot. Eventually we were able to map which lines on the menu were tastes, starters, mains, and sides, but to get this done meant literally taking out a piece of paper and a pen. I wish I was kidding: While negotiating with our servers about Lana Del Lame in background, we wrote our own translation of the Al’s Place menu, from hipsteraunt to English. After delivering an incorrect item with no explanation of what it was, they told us we should not have taken a bite before telling them it was wrong. How else were we supposed to find out what it was?!
The food is… fine. Their french fries were undercooked and soggy, but boy were they salty! Or should I say “brined.” The smoky mayonnaise alongside was too sweet and tasted like a dessert. Marlowe’s fries were better a decade ago. The Al’s Place lettuces were meant to be eaten by hand — see my queuing up for the bathroom sink, above — and for some reason had a bland avocado mousse streaked underneath. Can we please stop putting sauces under the food, to trick wraithy Instagrammers from LA into actually eating a sauce? The Progress does the reversed-salad-thing better. The chickpeas and harissa had some refrigerator burn to the legumes. The cold chickpea salad at Hey Day is better. The Al’s Place bean soup was overseasoned and was a bad seasonal choice to have on the menu during hot weather. But hey, they’ll put kimchee in it so you can think it’s exotic. Or something. The minestrone at any one of a dozen Italian joints in North Beach is better. The Al’s smoked brisket needed to have its fat better trimmed, and ended up tasting more lukewarm St. Patrick’s Day-corned-beef than cozy passover seder.
We only passed on one of our tastes of wine, so an actual professional was involved in their wine list at some point. They had no beers on draught, which is weak in a drinking town like SF. Also there is no hard liquor license, so your cocktails will be those sweet sherry & vermouth-heavy shims instead of a before-dinner classic like a Manhattan.
Al’s Place joins Hakkasan and The Progress as the two dinners that have me doubting the Michelin guide’s star ratings. The Michelin guide used to be insulated from silly trends and dopey culinary tricks, but they are clearly lowering their standards to appeal to teh youths. Al’s Place is also in that rarified competition of least bang for the buck, alongside the stunningly overrated and overpriced Hashiri.
Avoid Al’s Place like the plague. There are many San Francisco restaurants that do the quirky, opinionated, idiosyncratic faux-casual thing better.