Never underestimate the bandwidth of a station wagon full of tapes hurtling down the highway. [Andy Tanenbaum, 1989]
As someone who did a lot of computing before The Cloud or Dropbox was a thing, I have a little box of hard drives tucked away in my living room. A bunch of these drives will be paperweights by now, the ball bearings frozen-up or platters otherwise unreadable, but I would happily pay for the salvageable data to be thrown up on Amazon for posterity and my own nostalgia. I tried trickle-copying the data over our Sonic DSL connection, but things were happening at a geologic time scale. Enter Snowball, Amazon’s big data transfer service. You sign up and the service piggy-backs on your usual Amazon Web Services (AWS) billing & credentials. Then they ship you a physical computer, a 50 pound honking plastic thing that arrives on your doorstep via two-day UPS:

The first thing I noticed was a cleverly-embedded Kindle that serves as both shipping label and user interface:

The plastic enclosure itself opens DeLorean-style to reveal a handful of spooled cables:

You plug the Snowball into your normal 120V AC mains power, and boot the thing:

Next you install some AWS software on another machine on your network, and then use that software to copy data over the network to the Snowball itself:
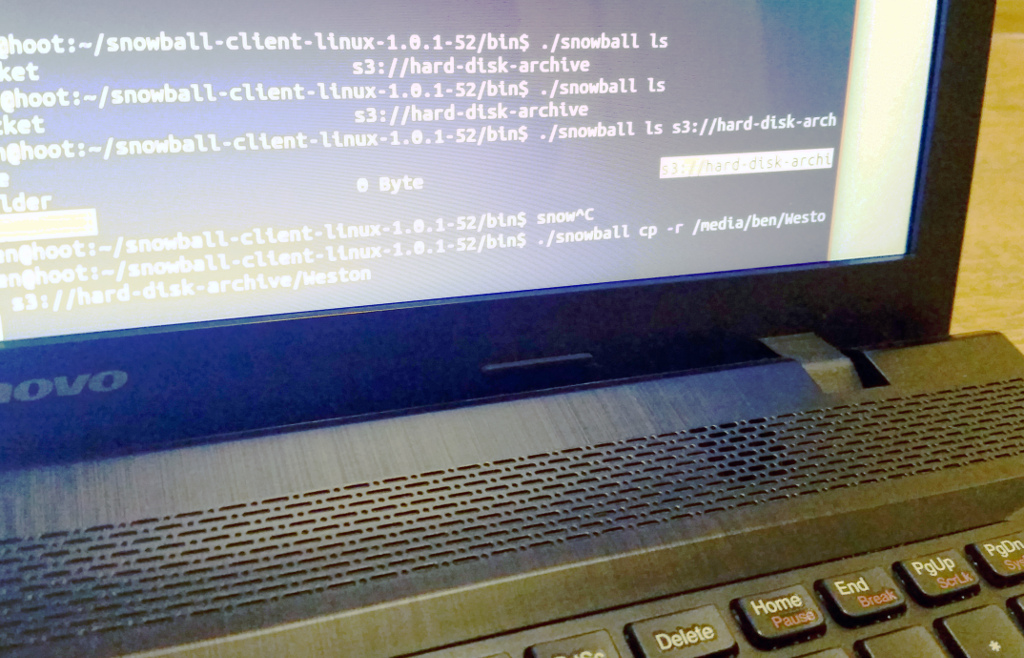
Tucked away inside is a serious amount of disk storage, 50 terabytes in the case of the Snowball I tried. The device itself is an intimidating “engineering sample,” whatever that means:

This is where I noted the first serious snag in my plans: The Snowball relies upon your own (home) network for data transfer, which puts a bandwidth bottleneck at your router. My suddenly-beleaguered Netgear thing was tapped-out within moments, and installing Linux on the router (WW-DRT) would not have gotten me further than a 2x speedup.
Also the Snowball client runs on another machine on your network, which is not much of a limitation when used in an institution. However I was copying data from an external hard drive sitting in a SATA IDE to USB 3.0 adapter thing, which put another bottleneck and layer of complexity at the USB port.
Why not just interface my external hard drives directly to the Snowball? Or maybe even install the hard drives as, temporary, internal disks within the enclosure? The enclosure is almost hermetically sealed (“rugged enough to withstand a 6 G jolt”), and exposes only Cat 5 and fiber network ports.
Here is me telling the Snowball via its command-line client that it is ready to be returned to AWS in Oregon:

So! I found the Snowball to be a relatively sophisticated and honest approach to the realities of the Internet bandwidth vs. storage size growth curve. However it is not a good solution for those of us wanting to upload a bunch of rotting hard drives to The Cloud. Amazon has a legacy service that accepted shipped disk drives directly, but I believe it has gone away. On the other hand, I expect Snowball to be a very efficient and slick solution for most organizations. But for the guy sitting on some dusty hard disks, it did not get the ball rolling.